Back to blog home
Building a Global Video Security Infrastructure (1 of 2)
by Team Rhombus, on January 3rd, 2018
Product UpdatesWhy we built it
When we started Rhombus Systems, we focused on a few product considerations that we were unwilling to compromise on.
- We were not going to require any on premise hardware (like a DVR/NVR).
- Setup had to be less than 5 minutes for each camera and should not require making any changes to the network.
- Watching video feeds (especially live feeds) had to be a pleasurable experience.
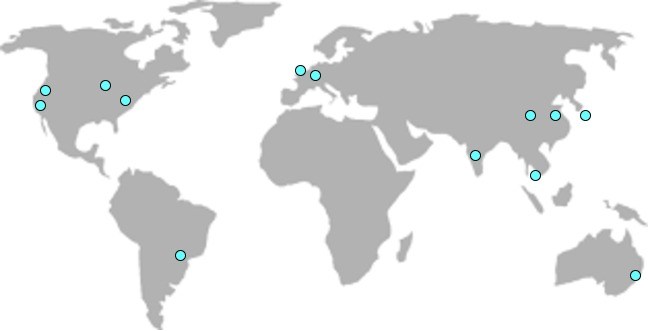
While all of these items are key to the vision of our product, the last one is the driver behind going global with our infrastructure. Without regional points of presence (POPs), physical distances create too big of a barrier to low-latency video streaming.
In order to provide true low-latency video feeds, we had to optimize the physical distance between 3 things: the video player (end-user), the camera, and our servers. But we realized that this physical requirement didn’t apply to the other 99% of operations that the camera and/or user performed. Replicating an entire infrastructure globally is REALLY hard (mostly because replicating data is hard), but replicating specific pieces of it can be substantially easier, especially if you understand how each piece benefits from being global (or doesn’t). In our case, there was no benefit to replicating data everywhere, we simply needed to reduce how far video segments had to travel across the world.
What we built
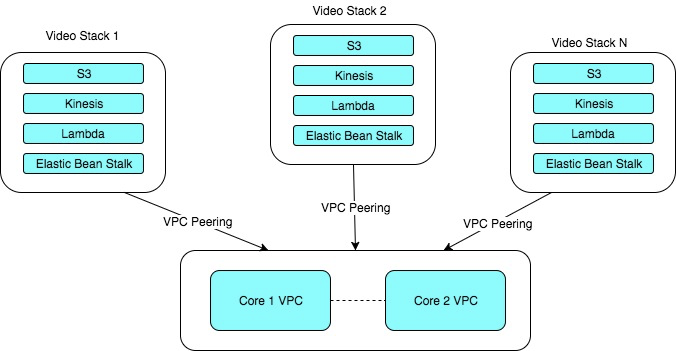
At this point, it’s probably appropriate to talk a bit about what we actually built. It could be described conceptually as a hub & spoke architecture, but technically it doesn’t meet the specific definitions of that. The general idea is that there are “N” regional stacks, made up of “M” Video Servers each. Each Video Server knows nothing about the other Video Servers in its stack (which means each region can scale horizontally), and each stack knows nothing of other stacks (again meaning adding N+1 stacks has no effect on existing stacks). Each stack takes about an hour to configure and provision (more information about this in Part 2), and is only limited by the number of regions AWS has available for use. As of the writing of this article, we have 8 regional stacks with 5 Video Servers each with 5 more regions planned for 2018.
At the center of the model, is what we call Core, which is actually an active/passive, dual-region stack, but for the sake of simplicity we’ll just refer to it as a single stack. Core is where all stateful information is kept, like customers, users, reports, etc, and is essentially a collective of JSON/HTTP webservices (we use Spring Boot + Jersey). It scales at a much different pace and direction than the regional video stacks, and is the foundation on which everything else is built.
What it does
When a camera starts up, it connects to an available Video Server (based on a round-robin algorithm) located in the region with the lowest relative latency (more on this in Part 2). This is a long-lived connection, and lasts for the uptime of the camera (assuming no network interruptions and whatnot, in which case it simply reconnects to a new server). When this connection is established the Video Server will register it in Core, so that it has a record of the exact server every camera is connected to.
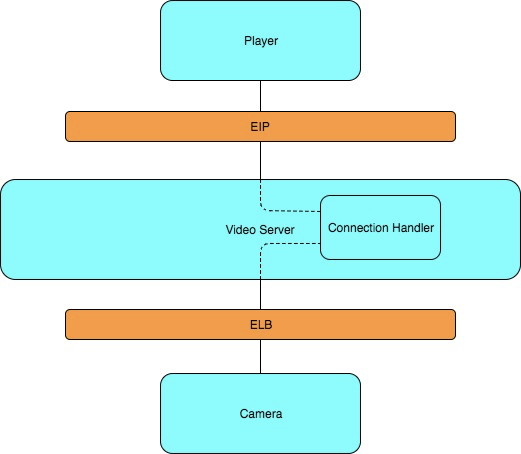
Now, when a user is ready to view a feed from their camera (from either their browser or mobile device), the player will ask Core for information about the server that the camera is connected to. It will then start making DASH requests directly to the specific Video Server that the camera is connected to through it’s Elastic IP. The Video Server creates a virtual tunnel between the player and the camera (it’s not actually a tunnel, but for all intents and purposes operates the same way as one), transferring data seamlessly in both directions. This approach enables us to accomplish some pretty cool things and stay true to our guiding principles.
- All camera connections are outbound over standard ports, meaning no changes to make on your firewall.
- Cameras and users will always find the shortest network route to each other. If me and my cameras are in Europe, I don’t need to bounce off servers in the US to view them.
- The overall solution scales nicely. As new geographic regions become available, bringing them online is a matter of clicks. And as current geographic regions become more heavily trafficked, adding capacity is automatic.
Conclusion
In technology, there’s always 50 ways to solve a problem, and so I believe it’s important to focus on solving your specific problem instead of the general one. As a result of our global infrastructure, we have happy customers all over the world that are able to experience the same snappy video player that we experience here in the US. It doesn’t matter that our data is here, or that the majority of our servers are here, as long as there is a regional POP near you (which we are always looking for new ones to bring up), you get the same experience as everyone else. In part 2 of this article, I’ll focus on the specific AWS technologies we are leveraging as part of our infrastructure.
%20--%3e%3csvg%20version='1.1'%20id='Layer_1'%20xmlns='http://www.w3.org/2000/svg'%20xmlns:xlink='http://www.w3.org/1999/xlink'%20x='0px'%20y='0px'%20viewBox='0%200%20110%20110'%20style='enable-background:new%200%200%20110%20110;'%20xml:space='preserve'%3e%3cstyle%20type='text/css'%3e%20.st0{fill:url(%23SVGID_1_);}%20%3c/style%3e%3cg%3e%3clinearGradient%20id='SVGID_1_'%20gradientUnits='userSpaceOnUse'%20x1='25.325'%20y1='766.725'%20x2='84.725'%20y2='707.325'%20gradientTransform='matrix(1%200%200%201%200%20-682)'%3e%3cstop%20offset='0'%20style='stop-color:%23006F94'/%3e%3cstop%20offset='1'%20style='stop-color:%2300C1DE'/%3e%3c/linearGradient%3e%3cpath%20class='st0'%20d='M106.9,47.5L62.5,3.1c-4.1-4.1-10.9-4.1-15,0L3.1,47.5c-4.1,4.1-4.1,10.9,0,15l44.4,44.4%20c4.2,4.2,10.9,4.2,15.1,0L107,62.5C111,58.4,111,51.6,106.9,47.5z%20M55.5,71.2c-9.4,0.3-17-7.3-16.7-16.7C39.1,46,46,39.1,54.5,38.8%20c9.3-0.3,17,7.3,16.7,16.7C70.9,64,64,70.9,55.5,71.2z'/%3e%3c/g%3e%3c/svg%3e)
Related Articles




