Back to blog home

Rhombus Product Insight – Face Detection: How Our Security Camera System Captures the Best Face
by Team Rhombus, on November 8th, 2018
Product UpdatesEfficient business operation and employee well-being starts with smarter technology. Here at Rhombus, we are dedicated in bringing powerful artificial intelligence features, such as facial recognition and people analytics, to provide organizations with incredibly intelligent video security. In this blog post, I want to share some insight into how one of our most popular features work. Let’s dive deeper into facial recognition and what we do to make it more enjoyable to use for our customers.
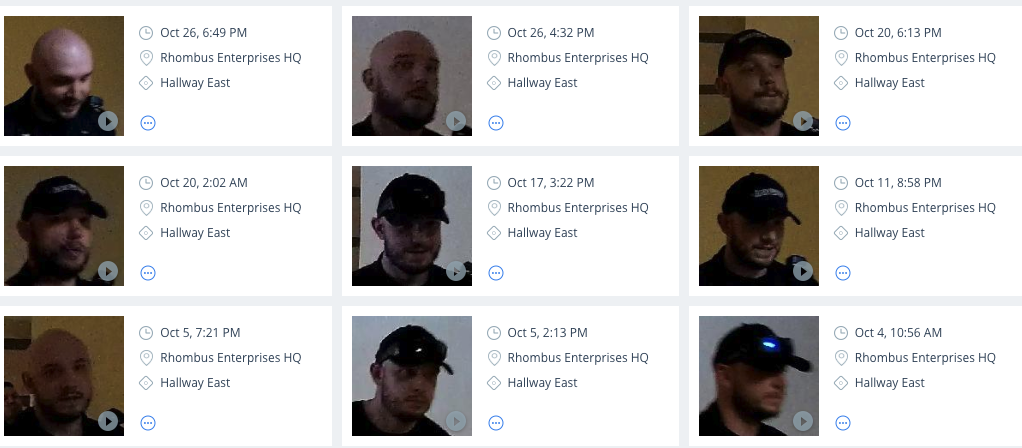
Facial recognition is a feature that makes us very different than existing systems in the market. As part of our facial recognition system, we store thumbnails of faces that each camera identifies so that you can search through them or be alerted when appropriate.

For each frame of a video clip, our facial recognition algorithm first uses a convolutional neural network (CNN) to detect all of the faces in view. Now for example, imagine we do this on a thirty second clip of three people walking down a hallway towards a Rhombus camera. In this brief thirty second clip, our system generates hundreds of different facial detections, here’s a formula to help demonstrate this.
3 people * 4 fps * 30 secs = 360 faces
This presents two challenges -
- It is inefficient to show you each of these faces when doing a search
- Running our facial recognition algorithm on each detection is too computationally heavy to issue prompt alerts.
One solution is to arbitrarily pick a small collection of faces from the list of detected faces and continue the analysis from there. As you can imagine, this can be a very inefficient way of going about it.
Let’s break this down and talk about how our system determines the best face for each person in a clip so that you don’t have to scrub through the video yourself to get that perfect snapshot of a person’s face.
Whenever we watch a video, we know how to track faces between frames. If we look at two frames of a video slowly, we are able to recognize a particular face even though the position of that face may change. Since a computer processes a single image at a time, a face detection algorithm can detect a face in two consecutive frames and have no idea whether the two faces belong to the same person.
To remedy this, we’ve implemented a multi-person tracking algorithm, which groups the detected faces into “people” across video frames. For each person in a frame, we either associate it with a person in the previous frame or mark a new person via a combination of logical predictions and neural network feature extraction. After this process has been completed, if there are three people in a clip, we have three groups of faces to analyze which we know correspond to different people.
Next, we still need to choose the “best” face for each person in the clip. Our goal is to find the most straight on face captured by the camera. Yet again (can you tell we like applying deep learning algorithms?), we apply another neural network to find the facial landmarks of each face and use this data to project a 3D human face into the image to compute the yaw, pitch, and roll of the face from the camera’s perspective. Choosing the face with the smallest yaw and pitch will provide the best face shot for that person.
This process allows us to narrow down hundreds of faces for a clip to the best corresponding face for each person. Not only does this provide prompt face alerts but it also ensures that only the ideal face shots of a person are shown in the console for a simple, enjoyable, and more accurate searching experience.
I hope you enjoyed learning more about Rhombus and what we do to ensure that our solution performs at the highest level for modern organizations. If you have any questions, or would like to learn more, you can reach us at any time!
%20--%3e%3csvg%20version='1.1'%20id='Layer_1'%20xmlns='http://www.w3.org/2000/svg'%20xmlns:xlink='http://www.w3.org/1999/xlink'%20x='0px'%20y='0px'%20viewBox='0%200%20110%20110'%20style='enable-background:new%200%200%20110%20110;'%20xml:space='preserve'%3e%3cstyle%20type='text/css'%3e%20.st0{fill:url(%23SVGID_1_);}%20%3c/style%3e%3cg%3e%3clinearGradient%20id='SVGID_1_'%20gradientUnits='userSpaceOnUse'%20x1='25.325'%20y1='766.725'%20x2='84.725'%20y2='707.325'%20gradientTransform='matrix(1%200%200%201%200%20-682)'%3e%3cstop%20offset='0'%20style='stop-color:%23006F94'/%3e%3cstop%20offset='1'%20style='stop-color:%2300C1DE'/%3e%3c/linearGradient%3e%3cpath%20class='st0'%20d='M106.9,47.5L62.5,3.1c-4.1-4.1-10.9-4.1-15,0L3.1,47.5c-4.1,4.1-4.1,10.9,0,15l44.4,44.4%20c4.2,4.2,10.9,4.2,15.1,0L107,62.5C111,58.4,111,51.6,106.9,47.5z%20M55.5,71.2c-9.4,0.3-17-7.3-16.7-16.7C39.1,46,46,39.1,54.5,38.8%20c9.3-0.3,17,7.3,16.7,16.7C70.9,64,64,70.9,55.5,71.2z'/%3e%3c/g%3e%3c/svg%3e)
Related Articles